Abstract
Despite the progress of 3D Gaussian Splatting (3DGS), reconstructing one-shot animatable 3D human avatars from a single image remains a challenging task. Existing 3DGS-based methods primarily rely on appearance observation and motion cues from monocular videos to reconstruct animatable 3D avatars. However, when applied to single-image setups, these methods struggle to extract accurate 3D features from a 2D image, limiting their ability to capture fine-grained appearance details and dynamic deformation, especially from challenging viewpoints. In this work, we propose SIAvatar, a novel single-image human reconstruction method that integrates diffusion-based appearance prior and parametric human model geometry prior within a 3DGS framework. Secondly, a vertex-based adaptive Gaussian densification scheme is introduced to effectively represent human geometry while mitigating artifacts. Extensive experiments demonstrate that SIAvatar generates realistic 3D avatars with plausible appearance details and novel pose animation from a single input image.
Pipeline
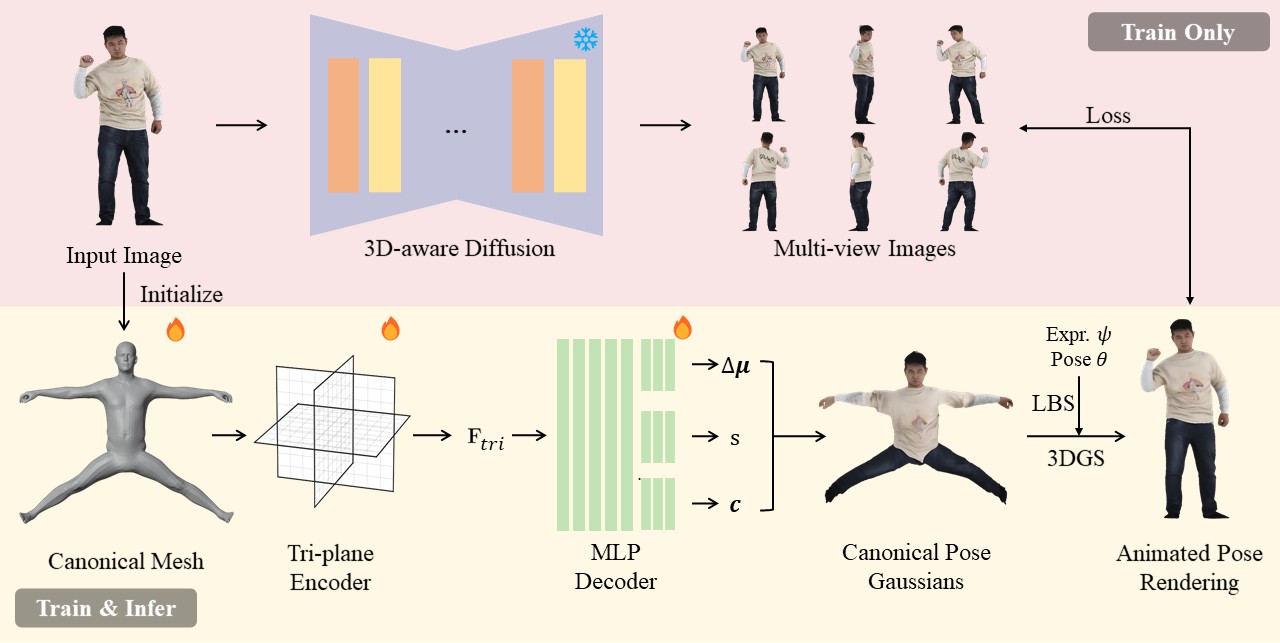
Overview of SIAvatar. Given a single image input, SIAvatar leverages diffusion-based appearance prior and SMPL-X geometry prior to regress the 3DGS representation of a 3D human avatar. During the inference stage, SIAvatar animates the 3D avatar by applying LBS to the 3D Gaussians using SMPL-X facial expression and pose parameters, and then renders the avatar as 2D images in arbitrary views.